lab03_Linear_Regression_and_How_to_minimize_cost¶
Original hypothesis¶
- Hypothesis : $H(x) = Wx + b$
- Cost : $cost(W,b) = \frac 1m \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$
Simplified hypothesis¶
- Hypothesis : $H(x) = Wx$
- Cost : $cost(W) = \frac 1m \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$
▷ What cost(W) looks like?¶
| x | y |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
¶
¶
¶
- W = 0, cost(W) = 4.67
- $\frac 13((0 * 1 - 1)^2 + (0 * 2 - 2)^2 + (0 * 3 - 3)^2))$
- W = 1, cost(W) = 0
- W = 2, cost(W) = 4.67
- W = 3, cost(W) = 18.67

▷ Gradient descent algorithm¶
- Minimize cost function
- Gradient descent is used many minimization problems
- For a given cost function, cost(W,b), it will find W,b to minimize cost
- It can be applied to more general function: cost(w1, w2,...)
How it works?¶
- Strat with initial guesses
- Start at 0,0 (or any other value)
- Keeping changing W and b a little bit to try and reduce cost(W,b)
- Each time you change the parameters, you select the gradient which reduces cost(W,b) the most possible
- Repeat
- Do so until you converge to a local minimum
- Has an interesting property
- Where you start can determine which minimum you end up

▷ Formal definition¶
$cost(W,b) = \frac 1m \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$¶
$cost(W,b) = \frac {1}{2m} \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$¶
$W := W - α\frac {∂}{∂W} \frac {1}{2m} \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$¶
$W := W - α\frac {∂}{∂W} \frac {1}{2m} \displaystyle\sum_{i=0}^{m}{2(Wx_i-y_i)x_i}$¶
$W := W - α\frac {∂}{∂W} \frac {1}{m} \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)x_i}$¶
- α : learning rate
- ∂ : partial differentiation for W
$W := W - α\frac {∂}{∂W}cost(W)$¶
- differential cost and multiply it by α(learning rate)
- subtract the calculated value from the existing W value
- update the result value to W repeatedly #### (The larger learning rate, the more rapidly W changes)
▷ Convex function¶
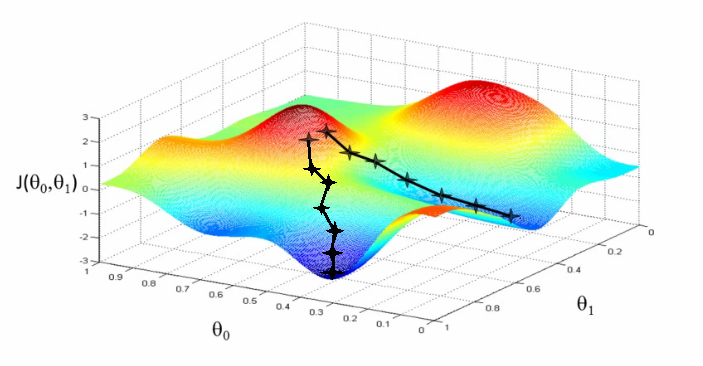
Local Minimum != Global Minimum ▶ we can't apply Gradient descent Algorithm

Local Minimum == Global Minimum ▶ we can apply Gradient descent Algorithm
We can be guaranteed the lowest point wherever you start
Simplified hypothesis¶
- Hypothesis : $H(x) = Wx$
- Cost : $cost(W) = \frac 1m \displaystyle\sum_{i=0}^{m}{(Wx_i-y_i)^2}$